Душан Павловић, LL.M. M.Econ.
Експерт за онлајн коцкање, докторски кандидат ЛАСТ-ЈД ЕМ студија, мастер права и мастер економије


Тумачење појма агрегација података (Енг. data aggregation) није јединствено, нити једноставно. Један од разлог за неунифицирано објашњење појма јесте разноликост контекста у којима се агрегација података може одвијати. Најопштије дефинисано, овај процес представља сврставање сакупљених података у скупове и подскупове. Конкретније, агрегацију података имамо код статистичких истраживања и њихових приказа. Свакодневно преко медија добијамо економске податке о просечном нивоу зараде, стопи инфлације, цени просечне потрошачке корпе или о расту тренда незапослености. Поред тога, информације о некој специфичној групи људи и њиховим карактеристикама (нпр. године старости, навике, запосленост, просечни ниво зараде) настају сложеним процесима прикупљања, анализирања, валидирања и систематизације података. То значи да у процесу истраживања најпре мора да се одреди простор или група која се истражује, затим да се дође до података, да се подаци сакупе, обраде и пре анализирања и презентовања, они морају да се сврстају у одређене категорије, тачније скупове. Очигледно, да би се дошло до статистичких приказа, поступак агрегација мора бити извршен. Свакако, савремена агрегација података има вишеструки значај, између осталог и за научне и пословне сврхе.
Агрегација података у пословне сврхе
Савремене компаније тешко да би могле да повећају сопствену конкурентност без агрегације пословних података. У пословном окружењу подаци се експоненцијално увећавају. Њихово сакупљање и обрада јесу велики изазов, а даља систематизација утиче на њихову употребну вредност. Процене пословног ризика и ефективности зависе од обраде података, као и њихове правилне агрегације. Треба имати у виду да благовремени и тачни финансијски извештаји (ако је могуће и у реалном времену) не представљају пуко испуњавање законских обавеза, већ и резултат пословања који може проактивно да утиче на савладавање потенцијалних пословних проблема, на раст базе клијената и повећање профитабилности.
Готово је свима који користе Интернет познато да рекламе које се појављују на друштвеним мрежама и различитим веб странама неретко имају некакве везе са нама. Колико то можда чудно било, комерцијалне поруке које нам се упућују могу бити прилагођене нашим потребама. Свакако да бихевиорални маркетинг (који може да се сматра новом научном граном, пословном стратегијом, делом примењене психологије, или све то заједно) служи за детекцију образаца понашања и за помоћ у избору маркетиншких стратегија. Његова суштина јеста да се маркетинг не сведе на пуко нагађање шта купци желе. Но, софистициране технологије које служе за повећање продаје робе и услуге преко Интернета користе и стратегије на бази агрегације података о потенцијалним конзументима. Преко Интернета добијамо понуде одређених врста роба и услуга иако раније нисмо показали било какво интересовање за њих. Штавише, узимајући у обзир наше године, место где живимо или чиме се бавимо, понуђена роба и услуге могу да нам делују јако интересанто. Обрадом наших личних података (године старости, пребивалиште и професија) нове технологије профилишу потенцијалне купце. Другим речима, нас као потенцијалне конзументе нове технологије сврставају у специфичне скупове потрошача којима се нуди одређена роба и услуге.
Груписање података по сродности може да се изврши по различитим критеријумима. Података има много и као што смо већ споменули, један од највећих савремених изазова јесте њихово сврставање и повезивање. Чињеница јесте да су наши лични подаци разбацани свуда по Интернету и то није нека новост. Велике компаније користе наше податке у најразличитије сврхе, али нам и нуде податке путем великог спектра услуга. Најочигледнији пример јесте Гугл који пружа услуге електронске поште, складиштења и обраде докумената, веб претраживање, мапе, праћење локација, друштвено умрежавање, дељење аудио и видео материјала и друго што може бити у интересу корисницима на Интернету. Пружањем својих услуга Гугл добија приступ личним подацима, прикупља их и врши њихову агрегацију према одређеним критеријумима. Свако ко има икаквог искуства са Гугловим услугама може да претпостави да је један од најважнијих критеријума за агрегацију података заправо сам корисник услуга. Другим речима, наши подаци се групишу у један скуп, а онда се разврставају у различите подскупове. Тиме се ствара садржај генерисан по кориснику (user-generated content). Овакав приступ за агрегацију података јесте основа за профилисање клијената. Профилисање свакако олакшава коришћење услуга и повећава њихов квалитет. Једноставно, агрегација податка утиче са једне стране на усавршавање пословне архитектуре привредних субјеката, а са друге стране обичним конзументима роба и услуга најједностваније речено – олакшава живот. У неку руку то звучи сјајано! Но, када се размотри проблем заштите приватности корисника онда ситуација и није тако сјајана.
Агрегација података и студије о коцкању
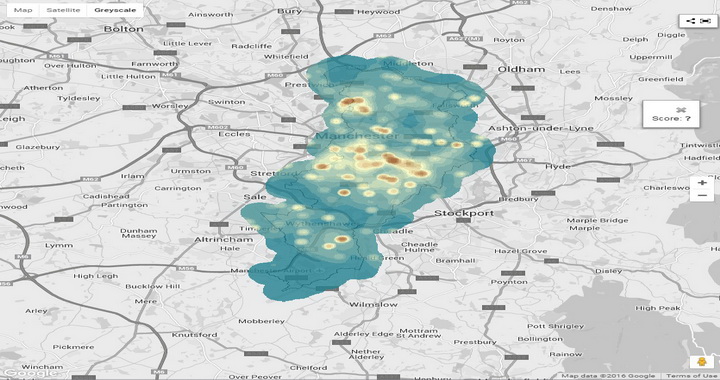
Да би смо указали на проблем заштите приватности, а у вези са агрегацијом података узећемо у обзир контекст коцкања, тачније мере које се тичу превенције проблематичног коцкања. У фебруару 2016. године, под покровитељством енглеских градова Манчестер и Вестминстер, а у сарадњи са удружењем локалних самоуправа Велике Британије објављена је студију о потенцијалним ризицима настанка проблематичног коцкања у одређеним географским областима. Циљ ове студије јесте да креира индексе ризика проблематичног коцкања путем идентификације категорија становништва које су изложене ризицима од настанка проблематичног коцкања. Поред студије, део пројекта јесте и мапирање географских области у Вестминстеру и Манчестеру са специфичним ризицима проблематичног коцкања. На основу постојећих извештаја и студија закључено је да су млади, лица која живе у сиромашним подручијима, грађани који спадају у специфичне етничке заједнице, лица са погоршаним менталним здрављем, незапослени и лица која траже третман за одвикавање од патолошког коцкања категорије становништва са повећаним ризиком од настанка проблематичног коцкања. Чињеница је да је већина студија у вези са коцкањем кванитативног типа код којих се посматра одређена појава или њен тренд у истраживаним групама (нпр. универзитетски студенти, незапослена лица, житељи неког насеља). Без намере да детаљније улазимо у методологије истраживања, свакако да је агрегација података део неопходне шире методологије обраде податка. Но, шта се дешава када се агрегација података комбинује са другим методологијама за процесуирање података? Инутитиван одговор би био да се тиме комплетира једно истраживање. Ипак, остаје питање да ли је гомилање методологија за обраду података заиста неопходно и сврсисходно?
Агрегација података и проблем приватности
Горе споменута студија има и своју другу димензију, која може бити проблематична са аспекта заштите приватности. Наиме, ова студија поред тога што идентификује ризике, она их и лоцира. На територијама Вестминстера и Манчестера (погледај линкове) лоцирани су различити ризици проблематичног коцкања. Неки од њих су оквирно лоцирани и тако предстваљени. Такав је случај са ризиком проблематичног коцкања код лица која се коцкају код куће (People at home gambling risk index). Но, радно способна али незапослена лица (economically active but unemployed residents) и лица из специфичних етничких група (residents form relevant ethnic groups) лоцирана су прецизно тако да се физичка адреса лица из ових група становника може пронаћи без већих проблем. Поред тога, прецизно су лоцирани објекти за смештај бескућника, центри за запошљавање, коцкарнице. Комбинацијом већег броја ризика тако што се лоцирају на мапи градова, затим визуелно преклопе и представе добијају се информације у којим деловима града постоји специфична концентрација ризика.
Свакако да је научно пожељно знати који се ризици проблематичног коцкања преклапају. Такође, из перспективе реализација јавних политика, добро је имати увид у којим деловима града постоје ризици и проблеми везани са коцкањем. Међутим, овај извештај има карактер јавног документа и доступан је преко Интенета. Постоји бојазан да овај документ може да утиче на стварање негативне перцепције о неком делу града, некој етничкој групи или особама које живе на одређеној адреси. Самим тим, постоји повећана опасност од злоупотребе научног истраживања, стварања предрасуда и дискриминације. Због ових података неко би могао да остане ускраћен за посао, зајам код банке или здравствено осигурање јер je препознат као лице са високим ризиком настанка проблематичног коцкања. Поред тога, живот у „погрешном комшилуку“ ствара сумњу сарадње са „погрешним људима“ (који можда имају сумњиву прошлост), те и вероватноћу да се посећују „погрешна места“. Такође, у „погрешном комшилуку“ постоји стрепња да ваше дете похађа школу или пак уопште зађе тамо. А управо онемогућавање прилике да се зађе у „погрешан комшилук“ можда утиче на нормални развој и социјализацију. У сваком случају пуно је начина да се читава насеља, породице или етничке групе дискриминишу захваљујући доступности података који у овом случају имају научни значај.
Начин на који горе описани пројекат задире у приватност није јединствен. Наиме одређена врста аналогије може бити направљена са веблинингом и редлинингом. Реч је о етички јако спорним процесима обраде личних података од стране финансијских институција. Циљ ових процеса јесте маприање локација (нпр. делови града) у којима социјално окружење утиче на процену финансијских вредности. У пракси то значи да уколико имате некретнину у одређеном делу града, њена вредност пада ако у вашем комшилку живи одређена етничка група. Поред тога, ако и ви живите у том насељу можда ћете морати да прођете неуобичајено детаљну проверу личне солвентности у процесу добијања позајмице од банке.
Приватност (ни)је мртва
Угрожавање приватности путем нових технологија више није табу тема. Јасно је да већ живимо у доба у ком је конвенционални облик приватности нестао. Но, развој нових технологија и научна достигнућа стварају нове начине којима се задире у приватност. На нама је да створимо етички дискурс у оквиру кога можемо да дискутујемо новине које имају позитивни значај али носе са собом потенцијалне претње. Овај текст је покушао да укаже на практичном примеру како једна традиционална научна методологија (агрегација података) уз помоћ савремених технологија генерише импозантне резултате, али и проблеме.
Photo: Map data ©2016 Google